Foundation-Models
Was sind eigentlich diese Foundation-Models und warum haben sie diese neue Welle von Ki ausgelöst? Was unterscheidet sie von den bisherigen Ki-Modellen und wie bewertet man sie eigentlich?
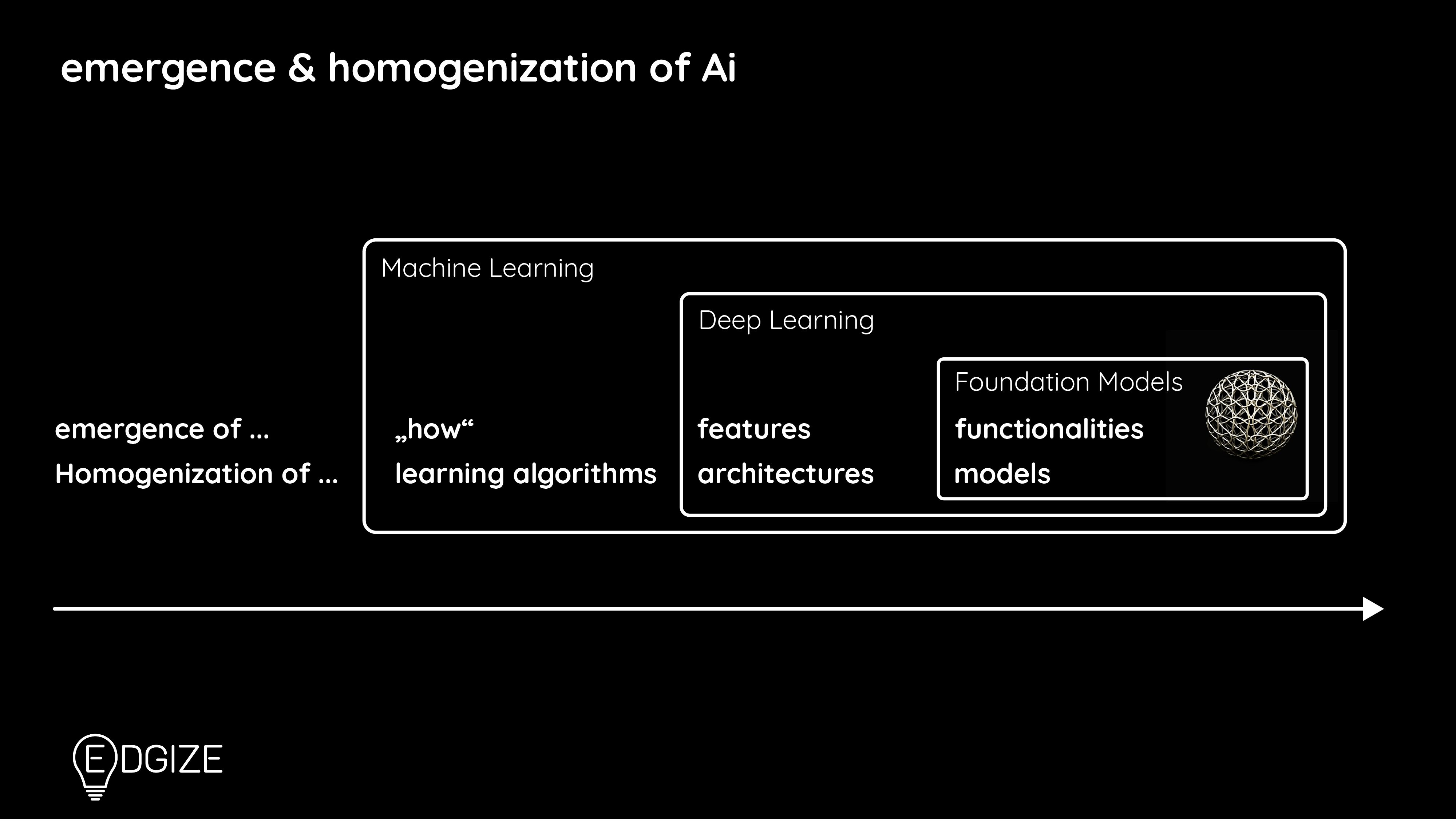
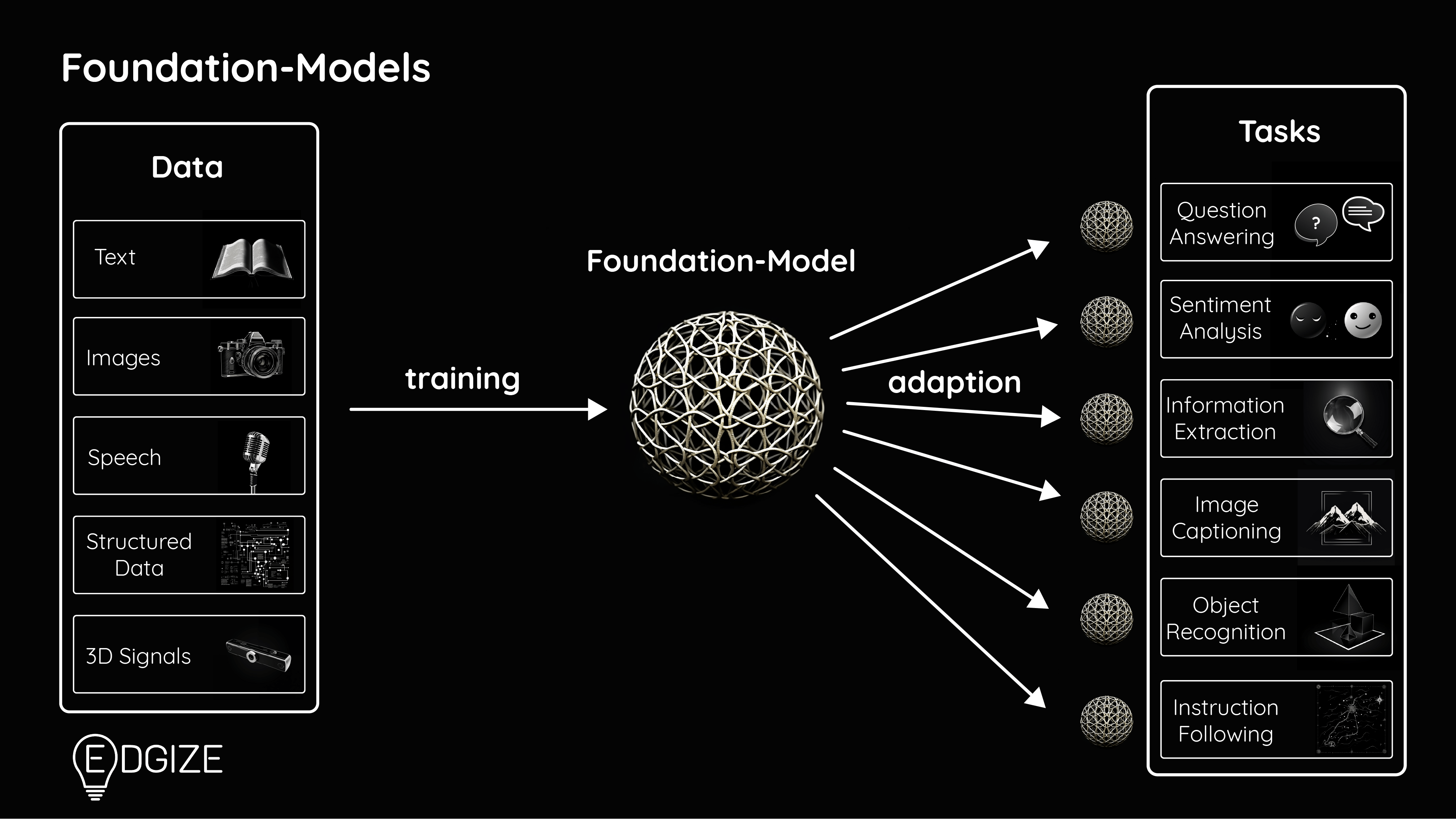
Foundation-Models sind sehr große KI-Modelle, die anhand riesiger Datenmengen und mit Hilfe von sehr großen Rechenressourcen trainiert werden. Sie können Text, Musik, Bilder und jetzt sogar Videos generieren. Zu den beliebtesten und bekanntesten Beispielen von Foundation-Models gehören zur Zeit GANs, LLMs, VAEs und multimodale Modelle. Die bekanntesten Tools bzw. Anwendungen dieser Modelle sind ChatGPT, Midjourney, BERT und Bing.
Die Zeit vor den Foundation-Models
„Alte“ KI-Systeme lösen bereits alle möglichen Probleme in der realen Welt. Jedoch erfordert dies bei der Erstellung und Bereitstellung jedes neuen Ki-Systems oft einen erheblichen Zeit- und Ressourcenaufwand. Denn für jede neue Ki Anwendung, die eine spezifische Aufgabe erledigen soll, musste ein großer, gut gelabelter Datensatz vorhanden sein. Wenn kein gut gelabelter Datensatz vorhanden war, mussten die Mitarbeiter Hunderte oder Tausende von Stunden damit verbringen, geeignete Bilder, Texte oder Diagramme für den Datensatz zu finden und zu labeln. Foundation-Models gehen hier einen innovativen, neuen Weg.
Was sind Foundation-Models?
Der Begriff „Foundation-Models“ wurde 2021 vom Center for Research on Foundation Models (CRFM) des Stanford Institute for Human-Centered Artificial Intelligence (HAI) geprägt. Hieran sieht man, dass es sich um eine recht neue Technologie bzw. Herangehensweise handelt.
CRFM definiert Foundation-Models als „jedes Modell, das auf einer breiten, ungelabelten Datenbasis trainiert wird (meist unter Verwendung von „unsupervised training“) und das an viele spezialisierte Aufgaben (z.B. mittels finetuning) adaptiert/ angepasst werden kann.“
Hier mehr dazu: „On The Opportunities and Risks of Foundation Models“
So sagt Percy Lang, CRFM-Direktor und Associate Professor für Informatik an der Stanford University: „Wenn wir von GPT-3 oder BERT hören, sind wir von ihrer Fähigkeit fasziniert, Text, Code und Bilder zu generieren, aber bemerkenswerter ist, wie diese neuen Foundation-Models unbemerkt und radikal die Art und Weise, wie KI-Systeme gebaut werden, verändern.“
Prinzipien der Foundation-Models
Riesige Datenmengen
Foundation-Models werden anhand riesiger Datenmengen trainiert.
So wurde zum Beispiel GPT-3, auf 500.000 Millionen Wörter trainiert. Dies entspräche 10 Menschenleben ununterbrochenen Lesens! Insgesamt umfasst GPT-3 175 Milliarden Parameter. GPT-4 hat bereits 1,7 Billionen Parameter.
Viele Daten und Parameter sind erforderlich, damit ein so großes Modell funktioniert. Dies bedeutet in der Praxis, dass man über sehr große finanzielle Mittel, Compute Ressourcen und Talente verfügen sollte, wenn man selber Foundation-Models entwickeln möchte.
Self-supervised Learning
In den meisten Fällen werden Foundation-Models auf Basis des Self-supervised Learning oder Varianten davon trainiert. D.h. es werden Milliarden oder Billionen von Parametern und Daten ungelabeled bereitgestellt. Die Modelle lernen so, aus den Mustern in den Daten die Antworten zu generieren.
Generalisiert
Foundation-Models sind so genannte generalisierte Modelle. Denn die meisten von ihnen sind nicht spezialisiert trainiert. Bei generalisierten Modellen sollten die Dateneingaben und Parameter so allgemein wie möglich sein, damit sie möglichst vielseitig einsetzbar sind.
Deshalb können Foundation-Models nach Bedarf auf spezifischere Anwendungsfälle angepasst und angewendet werden. Aus diesem Grundmacht es sie für viele Branchen und Industriezweige sehr nützlich.
Adaptierbarkeit
Ein großer Vorteil von Foundation-Models ist, dass sie wegen ihrer breiten generalisierten Wissensbasis durch transfer learning, instructions und Kontextwissen auf spezialisiertere Anwendungsbereiche angepasst werden können.
Arten von Foundation-Models
Es gibt verschiedene Arten von Foundation-Models. Zu den bekannteren zählen generative adversarial networks (GANs), transformer-based large language models (LLMs) und multimodale Modelle, die wir hier erklären werden. Darüberhinaus gibt es noch andere, wie beispielsweise Variational Auto Encoder (VAEs).
Computer Vision Foundation-Models
Computer Vision Modelle sind eine Art von KI-basierten Modellen, die es schon länger als den Begriff Foundation-Models gibt. In der Computer Vision werden viele verschiedene Arten von algorithmisch generierten Modellen verwendet. Sie gehören zu den der ältesten UseCases in der Geschichte der Ki bzw. der Vorstufe: des maschinellen Lernens. Computer Vision Modelle wurden früher eher durch convolutional neural networks (CNN) realisiert. Heutzutage verschiebt sich der Realisierungsfokus immer mehr zu Transformer basierten Entwicklungen.
Multimodale Foundation-Models
Multimodale Foundation-Models kombinieren verschiedene Datentypen beim Training z.B. Bild und Text oder Text und Audio. Diese semantische Korrelation zwischen den verschiedenen Datentypen erzeugt besonders vielseitig einsetzbare Foundation-Models.
Generative Adversarial Network
Generative Adversarial Networks (GANs) sind eine Art von Foundation-Model, bei dem zwei neuronale Netze in einem Nullsummenspiel gegeneinander antreten und konkurrieren. GANs sind nützlich für semi-supervised, supervised und reinforcement learning. Nicht alle GANs sind Foundation-Models; Es gibt jedoch mehrere, die in diese Kategorie passen.
Transformer-Based Large Language Models (LLMs)
Transformer-basierte Large Language Models (LLMs) gehören zu den bekanntesten und am häufigsten verwendeten Foundation-Models. Ein Transformer ist ein Deep-Learning-Modell, das die Bedeutung jeder Eingabe, einschließlich der rekursiven Ausgabedaten, abwägt.
Ein Large Language Model (LLM) ist somit ein Sprachmodell, das aus einem neuronalen Netzwerk mit vielen Parametern besteht. Diese Parameter bestehen aus Milliarden von ungelabelten textbasierten Daten, die normalerweise durch einen self-supervised Lernansatz trainiert werden.
Bewertungsmetriken von Foundation-Models
Es gibt verschiedene Arten der Evaluation und Bewertung von Foundation-Models. Davon lassen sich die meisten in zwei Kategorien einteilen: intrinsische Evaluierung (die Leistung eines Modells im Vergleich zu Aufgaben und Unteraufgaben) und extrinsische Evaluierung (wie ein Modell insgesamt im Vergleich zum Endziel abschneidet)
Es gibt unterschiedliche Arten von Leistungsmetriken mit denen Foundation-Models bewertet werden können. Aus diesem Grund wird für ein generatives Modell eine andere Leistungsmetrik verwendet als für ein Vorhersagemodell, da sie auf unterschiedlichen Prinzipien beruhen.
Die am häufigsten verwendeten Metriken zur Bewertung von Foundation-Models sind folgende:
- Präzision: Die wichtigste Metrik! Wie präzise bzw. genau ist das Foundation-Model? Präzision und Genauigkeit sind DIE KPIs, die in Hunderten von algorithmisch generierten Modellen verwendet werden.
- F1 Score: Kombiniert Präzision und „Recall“. Diese komplementäre Metrik erzeugt einen KPI zur Messung der Ergebnisse eines Foundation-Models.
- Area Under the Curve (AUC): Dies ist eine nützliche Methode zur Bewertung, ob ein Modell positive Ergebnisse anhand bestimmter Benchmarks und Schwellenwerte trennen und erfassen kann.
- Mean Reciprocal Rank (MRR): Dies ist eine Methode zur Bewertung, wie richtig oder falsch eine Antwort im Vergleich zur bereitgestellten Abfrage oder Eingabeaufforderung ist.
- Mean Average Precision (MAP): Dies ist eine Metrik zur Bewertung von „retrieval tasks“. MAP berechnet die mittlere Genauigkeit für jedes empfangene und generierte Ergebnis.
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE): Diese Metrik misst den „recall“ eines Modells und wird zur Bewertung der Qualität und Genauigkeit des generierten Textes verwendet. Es ist auch nützlich, um zu überprüfen, ob ein Modell „halluziniert“. Also ob das Modell eine Antwort generiert, bei der es sich praktisch um eine Vermutung handelt ohne diese kenntlich zu machen und die zu einem ungenauen oder auch falschem Ergebnis führt.